
towards retrieving suitable texts for foreign language learning
w. jonas reger
cs 447: natural language processing, computer science, university of illinois urbana-champaign
abstract
many are interested in acquiring skills in globally significant languages in a world that has become well-connected due to technology supporting high-speed transportation and communication. while foreign language education providers extensively use computational tools such as machine translation, there is still much room for new tools to support their learning objectives at a larger scale more efficiently. in this literature review, i discuss research in natural language processing (nlp) that contributes to measuring the suitability of texts from a foreign language learning perspective. in addition, i discuss text retrieval algorithms that lend autonomy to the user to personalize their foreign language learning experience.
1 introduction
as computational capabilities and text corpora have grown dramatically in recent decades, there is increasing potential for new nlp tools in the first (l1) and second (l2) language learning fields. because the demand for learning languages and the growth of text data has grown dramatically, many have opted to utilize large text corpora or other automatic educational tools and platforms. while many have succeeded in foreign (l2) language acquisition using these alternatives, nlp methods could make the process more efficient and reliable.
in particular, the motivation of this paper is to review recent research about retrieving relevant texts from corpus data for l2 learning. the research question i wish to answer in this review is “how can suitable texts be retrieved from large text corpora for l2 learning?” to answer this question, i will consider the following sub-questions; “how can the so-called suitability of texts be measured?” and “how can text retrieval algorithms be implemented to retrieve relevant texts for optimal learning?”
in section 2 background, i presented relevant background information for the reader to be aware of previous work or concepts related to the content of this review. recent research will then be reviewed and discussed across two main sections to answer the research questions. in section 3 literature review, i will review some previous works in the literature with some critique. in section 4 discussion, i will discuss the overarching topics to relate the results to each other and the research questions. in section 5 conclusion, i conclude my literature review with a brief overview of the conclusions and possible next steps for research.
2 background
suppose one considers more philosophical works; research in linguistic complexity spans over a century, possibly millennia. the beginning of modern approaches to measuring linguistic complexity is notably attributed to the early developments of readability formulas by flesch (1948) and dale and chall (1948). these early formulas were linear regression models fitted to only a few features of text characteristics, such as sentence length and average word count per sentence. since then, readability formulas or similar methods have been widely applied in many fields, particularly education and language learning. most early works developed procedures or models for language learning, and it was often assumed they could be applied interchangeably to l1 and l2 applications. in recent years, there has been more exploration of developing models specifically for either l1 or l2 or even both.
since then, more approaches to measuring linguistic complexity have surfaced to expand beyond lexical or syntactic complexity measures, including morphological, semantic, and discourse complexity measures. despite theoretical support for some of these approaches to be highly informative, only lexical and syntactic features are most informative and contribute to accurate predictions of text complexity. also, since 1948, more sophisticated methods have been developed for extracting features or generalizing information from texts, such as text parsers or statistical language models. a common issue in measuring linguistic complexity is that quantifying text characteristics is not a perfect method, as some information is always lost during feature extraction to generalize or model the data.
lastly, since the rise of extensive text corpora data, there have been developments in implementing text retrieval systems for l2 learning interests in recent years. traditional and modern text retrieval systems typically use algorithms such as ranking to rank pages most relevant to a given query. this general application is not sufficient for l2 learning, which is why there have been research interests in developing modified systems. such systems often incorporate l2 learning features in search functions such as complexity measures, topics, presence of target vocabulary, etc. additionally, topic modeling is a topic that seldom appears in the literature, yet many recent developments in topic modeling literature are promising for l2 learning research. despite the intensively technical nature of modern topic models, many approaches have been developed to improve coherent topic representations of corpus documents and improvements in modeling over smaller documents with more coherent topics. many of these developments can benefit corpus exploration and discover optimal sub-corpus documents for l2 learning purposes.
3 literature review
3.1 readability measures
heilman et al. (2007) covered various methods for modeling text complexity for l1 and l2 learning. text complexity measures are often used for language learning text retrieval systems. its relevance to l2 learning is fascinating since i am interested in methods of quantifying text complexity toward l2 learning.
motivation — heilman et al. (2007) had previously developed the reader-specific practice (reap) tutoring system, which retrieved suitable texts for foreign language learning. it utilized a readability scoring measure to retrieve texts of desired complexity for learners. however, they recognized important distinctions between l1 and l2 learning, which could impact the measurement accuracy.
heilman et al. (2007) found that l1 and l2 learners follow different learning timelines. l1 learners naturally learn the language from infancy, acquiring most grammatical knowledge before entering school. thus, corpus data for l1 learning has little grammatical change through the graded levels. instead, l1 texts have more lexical progression. l2 learners often struggle with grammatical knowledge, even in advanced grade levels. thus, l2 texts across graded levels tend to emphasize grammatical progression as much as lexical progression.
using lexical features — heilman et al. (2007) utilized statistical language modeling rather than a typical regression model. heilman et al. (2007) recognized that language models would handle shorter texts better and enable modeling probability distributions over all grades. i would also like to add that language models tend to generalize patterns in the text better than traditional linear regression models. so, language models would capture the contextual generalizations around words and offer better accuracy of readability predictions.
the model was a collection of traditional uni-gram language models with a uniform prior distribution for the grade level. the classification involved computing the log-likelihood that some text was generated from a language model of grade . whichever language model has the highest log-likelihood, its grade level is the predicted label of the text. while bi-gram or tri-gram models could generalize the language better and even capture grammatical information, heilman et al. (2007) says that uni-grams were better for smaller training data. additionally, heilman et al. (2007) wanted to distinguish between lexical and grammatical contributions, so uni-gram models focusing heavily on lexical information and less on grammatical information was another benefit. the log-likelihood formula is shown below (2007).
where is the number of tokens for the word type in vocabulary .
a common issue i have seen in many publications relating to modeling the readability of texts is the limitation of the corpus size. i think it would be worthwhile to explore ways to expand the corpus data to support higher-order n-gram language models, as they could be a valuable component of a general readability modeling method. however, the intention of heilman et al. (2007) to distinguish between lexical and grammatical feature-based models is a sound approach to what they aim to accomplish. another concern is that while the language modeling approach is exciting, it may still be somewhat unstable for text retrieval systems due to using course-grained readability scoring. exploring an alternative language modeling approach that factors in a more fine-grained measure may outperform the graded measure approach. there was also no mention of smoothing in the uni-gram models, which could improve the performance of predictions by giving some weight to unseen terms in new texts.
using grammatical features — since l2 learners focus more on grammatical progression than their l1 counterparts, heilman et al. (2007) developed a classification model for grammatical information to predict readability grades. they used the stanford parser (a software program that extracts the grammatical structure of sentences) to parse the text and extract patterns from parse tree structures using tgrep2 (a tool for searching grammar structure trees of grammatically annotated text data). this allowed them to extract grammatical constructions they deemed necessary for l2 readability. then heilman et al. (2007) computed the rate of observing these constructions per word.
a second set of grammatical features included part-of-speech tagging and sentence length. this provided heilman et al. (2007) with a comparison set of grammatical features to observe performance impact and computational expense tradeoffs. a third feature set of grammatical dependency structures could also be considered. while this set may not be generalizable to all languages, it may be an alternative worth exploring for english as a second language. although, it would be subject to similar computational expense concerns as the general structure parsing approach.
combining lexical and syntactic features — heilman et al. (2007) wanted to investigate the performance impacts of combining both models into one model. the grammatical classifier was an implementation of knn (k nearest neighbors) where the readability grade was assigned based on the trained neighbors near text . they added a confidence measure to the grammatical classifier’s predictions before adding it to the language model’s predictions. this confidence measure is the proportion of neighbors near text with the same label. the new prediction value is shown below (2007).
where is the lexical model’s prediction label, is the confidence measure, and is the grammatical model’s prediction label. this confidence measure was a great way to allow the grammatical-based model to contribute to the lexical-based model’s predictions without causing the model to overfit. a similar confidence measure could be implemented for the language model prediction, using knn to compare the classification labels of the text’s nearest neighbors. however, given that the language modeling approach works very well, it may be unnecessary. for morphologically complex languages, however, i think a lexical-based model would not perform as well as it does in english. so, a confidence measure for lexical-based model predictions may be necessary for languages more morphologically complex than english. also, a lexical-based model may not be realistic for some languages, so turning to alternative complexity measures for morphological features may be necessary.
findings — heilman et al. (2007) found that the lexical model outperformed the grammatical model when implemented independently. however, the combined model outperformed the lexical model. this indicates that interpolating scores between both models contribute toward more accurate predictions. heilman et al. (2007) also found that performance between the two grammatical feature sets across all models was comparable. this is a valuable insight since grammatical parsing can be computationally expensive for extensive corpus data, so part-of-speech tagging is a sufficient alternative. the language and combined models were also highly correlated with expert-generated grade labels of text data, as shown in table 1.
table 1: correlation of predicted labels to expert-generated labels for different models.
| test set (number of levels) | l1 (12) | l2 (4) |
|---|---|---|
| language model | 0.71 | 0.80 |
| grammar model | 0.46 | 0.55 |
| interpolated model | 0.72 | 0.83 |
| grammar2 model | 0.34 | 0.48 |
| interpolated2 model | 0.72 | 0.81 |
heilman et al. (2007) suggested that the cause of the performance disparity between lexical and grammatical-based models may be due to the parser’s sensitivity to noise in the corpus data. additionally, they suggest that the lexical-based model likely performed well for l1 and l2 texts because english is not a morphologically sophisticated language. the language modeling approach in their study may be unmanageable for morphologically complex languages. i think the results of this study may be a bit clearer with cleaner corpus data. in particular, heilman et al. (2007) discussed various features found in the texts that likely impeded the parser’s ability to extract enough grammatical information. i would suggest that more text-cleaning processes could be developed to prepare the texts for parsing and other feature extraction tasks. the presence of noise in the corpus is largely due to a lack of text pre-processing rather than the inherent structure of the texts they are targeting.
3.2 interactive topic modeling
hu, boyd-graber, and satinoff (2011) covered topic modeling on corpus data. while it is a detour away from l2 learning applications, it is relevant to classifying texts with topic labels toward text retrieval tasks. an l2 learner’s motivation may be more significant when accessing texts related to a topic of interest. classical and modern topic models are either unhelpful or too sophisticated for end-users with non-technical backgrounds to update topic models as needed. hu, boyd-graber, and satinoff (2011) discussed an interactive approach to updating topic models in a fast and user-friendly way, which may benefit instructors and learners alike.
motivation — hu, boyd-graber, and satinoff (2011) explored a modification of the classic latent dirichlet allocation (lda) model, in which they implemented interactive features for non-technical end users. they identified that while the industry has developed many modifications to enhance lda, many were inaccessible to users without machine learning or technical backgrounds.
adding constraints to topic models — topic models such as lda are simply non-deterministic multinomial probability distributions of latent topics over words and documents in a corpus. this information is summarized as terms with the highest probability in a topic to the user. often, this summary can be incoherent and frustrating to a non-technical user. hu, boyd-graber, and satinoff (2011) presented the implementation of “must-link” constraints to guide the topic estimations in the model, such that terms may appear together in the same topic. the constraints are essentially considered equivalent to a term under the multinomial distribution.
more underlying technical details of how lda models work are beyond the intended scope of this review. however, i wish to focus on the constraint methods and the interactive element discussed in the next section. there is a lot of potential for this topic modeling approach to be used in topic labeling toward l2 learning, especially given that it’s designed for end-users with a less technical background. so, this seemingly arbitrary topic may help explore topics in corpus data for l2 learning toward text retrieval interests discussed in later sections.
interactively adding constraints — if the topic model is static, estimating the distribution with constraints is the same as the classical method. however, hu, boyd-graber, and satinoff (2011) wanted to add an interactive element allowing end-users to update a topic model with new conditions. they used an unassignment algorithm to perform topic ablation. essentially, topic labels can be forgotten, and then the unassigned data is treated as new data to add to the model. this process is a signal from the user to the model that the topic distribution over some parts of the data is not coherent or is incorrect. they proposed four criteria for unassignment.
- all: unassign all topic labels. this is equivalent to simply estimating the topic distribution from scratch again. this is impractical as it does not allow any interactive updating of topics.
- doc: unassign all topic labels in documents that contain any words in constraints. this implies that a document may have incorrect topic labels and needs to be reset.
- term: unassign all topic labels for all tokens of words in constraints. this may allow words in constraints to be relabeled into the same topics, but surrounding words that form contexts cannot follow them to different topics.
- nothing is unassigned. while it may be sufficient in theory, hu, boyd-graber, and satinoff (2011) states that it may not be practical for end-users as they would feel like their inputs are not being added to the model. since the assignments are not changed, it is difficult for the constraints to overcome the inertia of the original distribution.
- each method is functional in the overall framework of topic modeling, but the doc and term unassignment methods are the most suitable options for incorporating interactive elements.
findings — hu, boyd-graber, and satinoff (2011) established the full and null (no constraints) methods as lower and upper bound baselines to compare the interactive methods against (lower is better). they found that doc ablation performed more favorably than term ablation since it gave enough freedom for the constraints to overcome the distribution inertia as it updates the distribution. the performance of each method is shown in figure 1 below. note that the doc method is more stable than other methods, as its error bandwidth shows.
figure 1: error rates of different ablation strategies over word constraints.
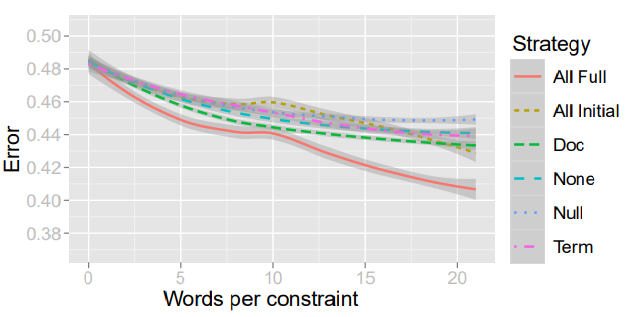
hu, boyd-graber, and satinoff (2011) also experimented with simulations and human users, finding that the simulation results well support the theory. however, the human users showed that human competence in attempting to constrain topics could impact model performance. however, some sensible constraints also did not lead to successful changes in topic distributions. regardless, hu, boyd-graber, and satinoff (2011) has shown a promising method of adding interactivity to updating topic distributions of corpus data, which i will discuss later in this paper.
one thing i would like to highlight is that the simulation was able to find optimal constraints more successfully than human users. i suggest implementing a feature in the application to “score” how well the constraints are expected to update the topic distribution. even further, optimal constraints could also be suggested to the user to alleviate some effort on their part. this allows the user to update the topic distribution interactively and offers some guiding features to support the user.
3.3 retrieval of reading materials
heilman et al. (2008) covers methods of preparing a corpus for optimized text retrieval for l2 learning. there is a discussion of including a topic search constraint in addition to text complexity constraints, which is not commonly seen in the literature. it also broadly discusses using query methods to search for and rank the most relevant documents according to some given search criteria. this is relevant to my research on retrieving suitable texts for l2 learning tasks.
motivation — heilman et al. (2008) wanted to develop a modification of an l2 tutoring system that could retrieve suitable texts for l2 courses. in particular, they wanted to design a system for the instructor to interact with and select readings that supported the learning initiatives of their curriculum. by extension, the retrieved texts would be tailored to the learners under the instructor’s supervision. heilman et al. (2008) wanted to implement search features to help facilitate text retrievals with pedagogically motivated constraints such as target vocabulary or text lengths.
creating and modifying a corpus — heilman et al. (2008) implemented web crawlers and a series of annotation and filtering processes to retrieve and generate a corpus data set suitable for l2 learning practices. while the web crawler is instrumental in the retrieval process, i am more interested in the downstream processes of modifying the corpus before text retrieval for l2 learning tasks. once the documents are scraped and collected into a large corpus, they undergo filters to remove any documents unusable for l2 learning, such as being too long or insufficient well-formed texts.
the documents are automatically labeled with a readability level using models similar to the ones described in section 3.1 readability measures. having the diversity of models based on lexical and or syntactic features allows the instructor to use search constraints more flexibly, such as finding texts with low syntactic complexity but high lexical complexity if vocabulary acquisition is the greater priority.
topic classifiers also label documents with predicted topic labels according to the topic categories used in the open directory project (odp). heilman et al. (2008) trained a classifier on odp documents and their gold-standard labels. this topic-label feature gives the instructor extra freedom to search for texts relating to a specific topic while searching for a set of target words. since single-topic assignments sometimes fail due to topic ambiguity, the system may assign multiple labels if necessary. one potential issue i would highlight is that this framework may not be flexible enough for new documents if the topic domain deviates from the one in the odp. a generalizable approach to topic labeling may yield better topic labels for future documents.
text retrieval — heilman et al. (2008) implemented a retrieval model using a ranking system similar to commercial search engines since l2 instructors usually would not require documents containing all the target words. so, the model tends to prefer documents with more variety of target word occurrences, thus allowing it to rank documents more appropriately for the instructor. the search tool interface is constructed in lemur (a toolkit for language modeling and information retrieval), with options to specify topics, target words, minimum and maximum reading levels, and minimum and maximum text lengths.
findings — results of log data showed that instructors generally need to submit approximately two search queries for every selected text document, implying the system may not be retrieving texts very well. however, human feedback from instructors suggested that the performance was satisfactory. instructors also only added search queries sometimes, implying that the content of readings was less important than finding readings with target words. after the experiment (end of the semester), the students were evaluated and given a survey. results show that the text retrieval system showed that students scored 89% on average, compared to 50% from an experiment using an older system. however, heilman et al. (2008) recognized that the results might be skewed due to the new system’s ability to be personalized for the course. so, students were directly tested on material they had seen before. i would recommend setting up a treatment and control group experimental design to compare the beneficial impacts of the system against not using the system. due to fundamental differences, a direct comparison between the old and new systems may not be possible. however, whether or not the new system affects l2 learning can still be evaluated in future studies.
3.4 text retrieval for language learners
lee and yeung (2021) covered a different approach to text retrieval that focuses solely on one measure of text complexity. the system’s simplicity helps us understand how the system performs over time as a simulated l2 learner acquires more vocabulary. so, this is relevant to my second research subquestion since effectiveness over time is implicitly related to the system’s general ability to retrieve relevant text for l2 learning.
motivation — lee and yeung (2021) wanted to investigate the performance tradeoffs of using the traditional rough-grained graded vocabulary in l2 learning compared to a more fine-grained approach that fits the users’ knowledge more closely. in particular, they wanted to evaluate text retrieval performance as the learner acquires a more extensive vocabulary and the effort the user requires to update the model vocabulary set over time.
text retrieval framework — the criterion used for text retrieval is the new-word density (nwd), which helps search for documents with similar nwd relative to the users’ vocabulary knowledge. lee and yeung (2021) chose this metric because it is simpler to interpret and more personalized to the user than the graded approach.
lee and yeung (2021) generalize their modeling approach by using an abstract concept of an open learner model (olm) to simplify the evaluation process of the text retrieval system. there are many methods for automating the estimation of the vocabulary knowledge for the user, but the authors opted for a manual updating approach. their reason is that the user would guide the estimation process and be less prone to error.
the retrieval model is evaluated based on the nwd error (actual nwd - predicted nwd) and the nwd gap (actual nwd - target nwd). the actual nwd for the user is (2021):
where is the number of words in a given document, if the user knows , and otherwise. while this is a simple measure of vocabulary complexity, i agree with their intent to simplify the criterion and model design to understand the performance impact on text retrievals over time. this approach helps expose why the rough-grained graded-level approach to measuring text complexity is generally suboptimal to the fine-grained approach from the perspective of l2 learning.
lastly, lee and yeung (2021) ran simulations of a simulated user reading documents obtained by the text retrieval algorithm over time. as the user reads documents, their vocabulary knowledge updates as new words are encountered. the algorithm’s goal is to retrieve documents with the highest nwd under the target nwd provided by the user (i.e., minimize the nwd gap). lee and yeung (2021) ran simulations using this olm format, assuming the simulated user consistently updates the model’s content. to simulate a more realistic user, lee and yeung (2021) implemented a user that updates half of the new vocabulary encountered. lee and yeung (2021) also simulated a user using the text retrieval system with the graded vocabulary as the retrieval metric instead of nwd. the graded approach consists of the user starting at a given grade and then reading documents at that grade level until the optimal time for the user to be promoted to the next grade.
findings — lee and yeung (2021) found that the olm approach yielded more stable text retrieval performance than the graded approach. the olm approach consistently stayed below the target nwd set by the user, so it never retrieves text that is too challenging for the user. it also never exceeds an nwd gap of 2%, so it stays close to the target. meanwhile, the graded approach in the beginning half of the simulation (before grade promotion) returns documents with diminishing nwd (nwd gap approaches 5%). so, the user is relatively less challenged as they acquire vocabulary for that grade level. when the user is promoted to the next grade, there is a significant spike in nwd of returned documents over the target nwd. this means that the user will be given more challenging texts than desired. the results of the “occasional” updating user were more prone to over-estimating the nwd of documents, which led to slightly large nwd gaps, but still below the target nwd. the simulation results can be viewed in figure 2 below.
lee and yeung (2021) also tested the approaches on simulations with different target nwds. an exciting trend they discovered was that the nwd gap increases faster as the target nwd is increased. lee and yeung (2021) suggested that text retrieval becomes more difficult as users request more complex documents that contain advanced vocabulary (i.e., higher target nwd). however, i think this conclusion incorrectly implies that the text retrieval system was the source of this issue. the performance impact on the retrieval algorithm is likely due to the corpus data and the user’s learning rate rather than the algorithm itself. if a user sets a high target nwd fixed for a long time on a finite corpus, the user will eventually acquire an extensive vocabulary. this large vocabulary could cause corpus “burnout,” where there could be a scarcity of documents near and below a high target nwd.
figure 2: actual new-word density (nwm) of the top-ranked document retrieved by the graded approach vs. the olm (full update) approach over time with a target nwd of 20%.
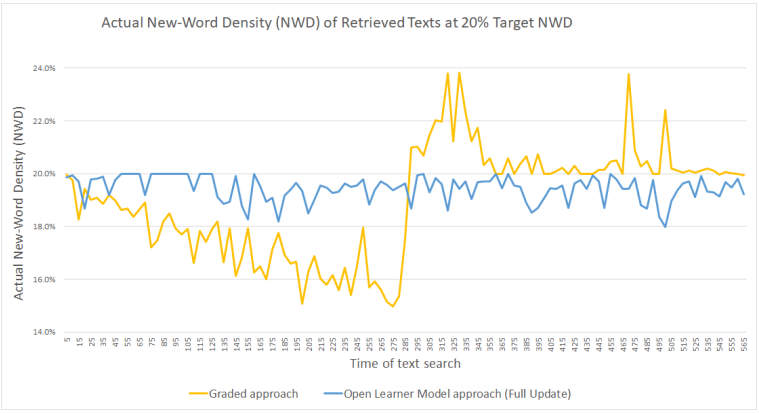
4 discussion
4.1 towards measuring text suitability
before retrieving relevant texts for l2 language learning, there must be some criteria of what factors determine the textual value and how to measure or quantify such value. in this section, i will discuss some aspects of the previously summarized papers related to this task.
text complexity — since reading is one of the core exercises in l2 learning that contributes to the learner’s success in language acquisition, it is essential to find texts that are suitable to their needs quickly. one common way to measure text suitability for l2 learning is text complexity. i saw this extensively from heilman et al. (2007) when they used uni-gram language models to generalize lexical complexity and predict readability grade levels of test texts. heilman et al. (2007) used parsers to extract syntactic structures and part-of-speech tags to generalize syntactic complexity. while these methods are more sophisticated than traditional methods often discussed in the literature, they capture stronger generalizations that improve performance in predicting text complexity for l1 and l2 texts.
alternatively, i saw a more straightforward metric used by lee and yeung (2021), new-word density. while this does not quite capture the same amount of information as more sophisticated measures, it is more adaptable to an individual’s l2 knowledge. in other words, this metric can be used for a more fine-grained measure of text complexity, while the more sophisticated approach is limited to a coarse-grained graded-level measure of text complexity. in isolation, both systems seem sufficient for measuring text complexity. however, as i saw from lee and yeung (2021), the text retrieval process from the perspective of l2 learning can be sensitive to coarse-grained measures.
a possible solution could be introducing an interpolation procedure between grade levels to help stabilize the transition as the learner is promoted. this transition measure may need to be evaluated or tuned. it has the potential to introduce smoothing over the unstable variation of measure gaps seen in the simulation of a learner using the graded vocabulary approach (lee and yeung (2021)).
text topics — many approaches to measuring text suitability for l2 learning primarily focus on complexity measurements. however, the topic of texts is often overlooked in the literature. it should be valued because l2 learners may be more motivated to acquire a new language when the texts they read align with their interests. there is also a practical aspect to consider as well. for instance, a learner who wants to visit a foreign country may be more interested in tourism or travel-related topics as those would be more practical than a topic like biology. another issue is that topic diversity may increase as text complexity rises. in other words, new topics may open up as a learner reaches a certain level of proficiency.
while it has been shown in heilman et al. (2008) that topic interest is generally not included in queries to their text retrieval system, i think that topics are still helpful for l2 learning tasks. one reason why it may be undervalued in their study may be because their primary users were instructors. instructors have more pedagogical interests that may not need to be aligned with topical interests to achieve teaching objectives. this is also not representative of the student’s interests. this was not a significant issue in their study since there was a tradeoff between individual personalization and course-oriented objectives. in other words, students benefited from working collaboratively under a structured curriculum, accommodating any loss of personal motivation they may have incurred. i suspect that topical searches may be higher if the system was used by learners guided by their interests.
additionally, the topic classifier used by heilman et al. (2008) was relatively abstract and may not be expressive of the actual topic distribution in the corpus. it does have the benefit of being simple and universal in practice. however, i think the recent literature on topic modeling practices has much more to offer to corpus explorations toward l2 learning. in particular, the work by hu, boyd-graber, and satinoff (2011) is an exciting example of creating an interactive variant of the lda topic model that can be updated in an accessible manner for users of non-technical backgrounds. this has strong potential for usage in l2 learning applications as most individuals learning languages may not be familiar with machine learning practices on average. this interactive and accessible environment could guide learners to explore corpus data independently by modeling a topic distribution over documents. this would produce more expressive representations of topics than the odp approach used by heilman et al. (2008).
4.2 towards text retrieval
since language acquisition is highly dependent on the learner’s practice of the language, in particular their reading, there is a need for effective methods of retrieving relevant documents from large text corpora. as i have reviewed and discussed in prior sections, there are various factors to consider when measuring the value of documents for l2 learning. this section will discuss some aspects of the previously reviewed papers related to this task.
retrieving suitable texts — in my review and discussions over approaches to measuring text suitability, i have briefly mentioned numerous times how they impact text retrieval systems. both sides of retrieving suitable texts for l2 learning are well connected. in particular, the groundwork for developing an accurate text retrieval system is the development of text suitability measures. the first part was designing measures of general characteristics such as text complexity and topic distribution of documents. the second part relates that information to an l2 learner’s language proficiency. this relative measure is where the suitability of texts is derived from. so, measures of text suitability can vary based on the system. still, the general idea is that the deviation between the learner’s target and the results of the retrieval system should be minimized.
i saw in heilman et al. (2008) that there was not much deviation from the instructors’ search queries and the search results, at least not enough to be frustrating or satisfactory to the user. however, this was implemented under a pedagogically motivated environment and may not perform the same for independent learner-driven settings. alternatively, i saw in lee and yeung (2021) that text retrieval performance was sensitive to coarse-grained measures and outperformed by fine-grained measures. since the framework of the simulation assumes an independent learner, there is a possibility that fine-grained measures may be optimal for independent learning (lee and yeung (2021)). meanwhile, the tradeoff to using coarse-grained measures may not be as negative if implemented with an instructor to guide the course in the pedagogical setting. so, even the impact of different measures on text retrieval systems may also depend on the learning environment, whether it’s independent or expertly driven.
autonomy for learning — an essential part of learning is autonomy for the learner or instructor to choose how to shape the learning experience. a core component of the text retrieval systems introduced by heilman et al. (2008) and lee and yeung (2021), as well as the interactive topic model introduced by hu, boyd-graber, and satinoff (2011), is the autonomy the systems lend to the user. heilman et al. (2008) shows that the autonomy in their text retrieval system enabled instructors to search for a variety of documents with a lot of freedom that reflects pedagogical interests such as constraining target vocabulary words or constraining document sizes to ensure readings are relevant to the curriculum as well as not too short or long.
the text retrieval system developed by lee and yeung (2021) showed a different kind of autonomy that was simpler and easier to interpret for the user. even with the simple measure, the system consistently met the user’s preferred text complexity and returned suitable texts. while the system did show corpus “burnout,” as i call it, it was at a high new-word density rate of 40%. typically, 20% would be realistic for challenging the learner, according to lee and yeung (2021).
lastly, the interactive topic model by hu, boyd-graber, and satinoff (2011) showed promise for being a resource to l2 learning for exploring new corpus data to motivate topical guided text retrievals for more specific topics such as “world travel” or “korea” if they presented themselves in the topic distribution. this is not necessarily a better alternative to the query search system proposed by heilman et al. (2008), but exploring corpus data could inspire further exploration of an existing topic. for instance, let there be a topic on “east asian cuisine” in the corpus which may not be listed in the odp topic lists. a learner has a latent interest in this topic but is not likely to search it independently (i.e., they are not thinking of it or do not expect it to exist in the corpus). thus, having this interactive topic model as a component of the more extensive system to help the learner explore the corpus data will help expose the learner to the knowledge that the topic exists. now the learner’s latent interest is drawn out and becomes a motivator for language acquisition in a topic they are interested in.
5 conclusion
in this paper, i have answered the research question by looking at how to measure the suitability of texts for l2 learning and how to retrieve relevant texts from large corpora for l2 learning. i reviewed four publications relating to measuring text complexity, interactively updating and refining topic models, and implementing text retrieval systems with autonomous features using different measures of text suitability. then, i discussed how these different bodies of work relate to each other towards the goal of answering the overarching research questions. i found that the granularity of measures for text complexity can impact the performance of retrieving relevant texts. however, i identified a possible confounder that suggests the learning environment may also interact with how well these different measures work for the task. a proposal for the next steps includes two implementations to explore. the first is to explore methods of integrating more robust interactive features, such as the interactive topic model, for a more expressive exploration of topics in corpus data. the second is to introduce a smoothing technique, such as interpolation with a transition measure, to allow the utilization of coarse-grained measures with more stability in text retrieval performance as learners promote to the next grade level.
6 references
- heilman, michael, kevyn collins-thompson, jamie callan, and maxine eskenazi. 2007. “combining lexical and grammatical features to improve readability measures for first and second language texts.” in human language technologies 2007: the conference of the north american chapter of the association for computational linguistics; proceedings of the main conference, 460–67. rochester, new york: association for computational linguistics. https://aclanthology.org/n07-1058.
- heilman, michael, le zhao, juan pino, and maxine eskenazi. 2008. “retrieval of reading materials for vocabulary and reading practice.” in proceedings of the third workshop on innovative use of nlp for building educational applications, 80–88. columbus, ohio: association for computational linguistics. https://aclanthology.org/w08-0910.
- hu, yuening, jordan boyd-graber, and brianna satinoff. 2011. “interactive topic modeling.” in proceedings of the 49th annual meeting of the association for computational linguistics: human language technologies, 248–57. portland, oregon, usa: association for computational linguistics. https://aclanthology.org/p11-1026.
- lee, john, and chak yan yeung. 2021. “text retrieval for language learners: graded vocabulary vs. open learner model.” in proceedings of the international conference on recent advances in natural language processing (ranlp 2021), 798–804. held online: incoma ltd. https://aclanthology.org/2021.ranlp-1.91.